
1. 배열, 문자열
2. 연결 리스트
3. 스택, 큐

1. 배열, 문자열
배열
여러 개의 동일한 타입의 데이터를 한번에 만들때 사용하는 자료구조입니다.
배열 이름이 상수 포인터의 역할을 하여, 주소로 참조합니다. (첫 번째 인덱스의 주소)
2차원 배열은 첫번째 인덱스가 행, 두번째 인덱스가 열을 의미하며 보통 테이블 처럼 생각하면 됩니다.
하지만 실제 메모리 상에서는 그냥 쭉 나열되어 있는 형태입니다.
배열의 장점으로는 빠르게 데이터에 접근할 수 있고, 배열 생성 이후 데이터를 관리하기 편합니다다.
하지만 배열을 전부 사용하지 않으면 메모리 공간 낭비가 생길 수 있습니다. 동적으로 데이터를 관리하기도 힘듭니다.
문자열
char형이 단어 1글자 밖에 담지 못해서, 문자열을 표현하기 위해 char형 배열을 사용했었습니다.
이때 글자 수+\0 (NULL문자, 문장의 끝)으로 저장하였습니다.
이후 많은 언어에서 String형의 데이터 타입을 만들어 문장을 표현할 수 있게 되었습니다.
String형 역시 char형의 배열 느낌이라, 글자 하나 하나를 인덱스 형식으로 참조할 수 있습니다.
ex)[JAVA] charAt(int index) - 인덱스에 있는 문자 반환, indexOf(char a) - 해당 문자가 있는 인덱스 반환
2. 연결 리스트
연결리스트는 각 노드(단위)가 데이터와 포인터를 가지고 연결되어 있는 방식으로 데이터를 저장합니다.
필요할 때마다 노드를 동적으로 생성하여 연결할 수 있고, 실제 메모리 상에선 연속적이지 않아도 괜찮습니다
주요 연산
삽입
중간에 삽입할 시, 삽입할 노드의 포인터가 뒷 노드를 가르키게 한 뒤 앞 노드의 포인터를 삽입할 노드로 변경하기
맨 뒤에 삽입 시 그냥 포인터로 가르키기
삭제
중간에서 삭제 시 삭제할 노드의 포인터가 가르키는 노드를 그 앞 노드가 가르키게 하기
맨 뒤에 삭제 시 그냥 포인터 삭제
탐색
헤드에서부터 순차적으로 탐색할 수 밖에 없음.
단일 연결리스트, 이중 연결리스트, 원형 연결리스트 등이 존재합니다
3. 스택, 큐
스택

후입선출(LIFO)형 구조 = 맨 마지막에 들어온 애가 맨 처음으로 나감
입력과 출력을 한 방향에서 제한한 자료구조로, Top으로 맨 위를 표시합니다.
함수 호출에서 복귀 주소를 기억하는데 사용하고, DFS 탐색에서도 사용합니다.
pop -> 맨 위 요소 뽑아오기
peek -> 맨 위 요소의 값만 얻어오기
push -> 값 넣기
큐
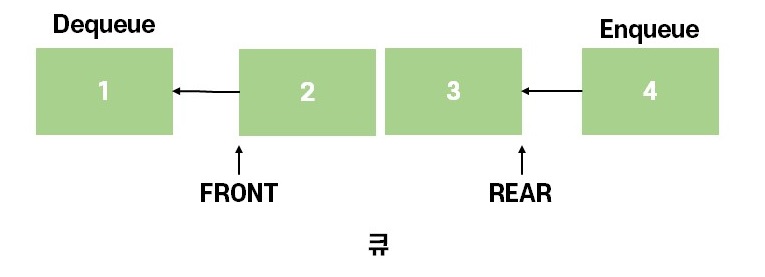
선입선출(FIFO)형 구조 = 나중에 들어온 데이터가 먼저 나감
한쪽 끝에서만 자료를 넣고 뺄 수 있는 자료구조
삽입이 일어나는 곳을 후단(Rear), 삭제가 일어나는 곳을 전단(Front)라고 합니다.
cpu와 주변 기기 사이에서 순서대로 일을 스케쥴링 할 때 사용합니다. BFS 탐색에서도 사용합니다.
Enqueue -> 큐의 맨 뒤 요소 추가, Dequeue -> 큐의 맨 앞에 있는 요소 뽑아오기

환형 큐는 Front와 Rear의 값이 배열의 끝에 도달하면, 다시 0으로 되도록 원형처럼 이어진 모양의 큐입니다.
Front는 큐의 첫 번째 요소의 앞을, Rear는 마지막 요소를 가르킵니다.
이때 항상 한 자리를 비워놔야 합니다. (공백과 포화를 구분하기 위해)
공백상태 : Front와 Rear가 같을 때(Front == Rear)
포화상태 : Front가 Rear보다 하나 앞에 있을 때 (Front % size) == (Rear+1 % size)
우선순위 큐는 큐 내부가 우선순위 별로 정렬되어 있는 형태입니다.
주로 Heap으로 구현되고, 가장 우선순위 높은 노드가 먼저 Dequeue됩니다.
덱

덱(Double ended queue -> Deque)은 양쪽 끝에서 모두 자료를 넣고 뺄 수 있는 큐입니다.
Front와 Rear로 나누어져 전단, 후단 모두에서 입출력이 가능합니다.
'알고리즘 > 스터디' 카테고리의 다른 글
| 6. 정렬 (1) - 삽입 정렬, 버블 정렬, 퀵 정렬 (0) | 2020.08.12 |
|---|---|
| 5. 재귀 호출 - 완전 탐색, 동적 프로그래밍 (0) | 2020.07.31 |
| 4. 비트 조작 - 비트 연산자, 비트 함수 (0) | 2020.07.31 |
| 3. 자료구조 (3) - 힙, 구조체 (0) | 2020.07.25 |
| 2. 자료구조 (2) - 트리, 그래프 (0) | 2020.07.25 |
Comment