
1. Epoch 늘려보기
2. CNN 수정
3. Dropout

파이토치로 지난번에 만든 사진 분류모델의 성능 향상을 해보려고 한다.
1. Epoch 늘려보기
우선 가장 쉽게 생각한 방법은 Epoch, 즉 사이클 횟수를 높히는 방법이다.
반복횟수를 20번으로 높혀서 실행하고 정확도를 확인해보았다.
구글 Colab에서 CUDA환경을 사용하였기 때문에, Batch-size를 16으로 늘리고 진행하였다.
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(20):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print('Finished Training')
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)Accuracy of the network on the 10000 test images: 65 %
Accuracy of plane : 68 %
Accuracy of car : 80 %
Accuracy of bird : 54 %
Accuracy of cat : 53 %
Accuracy of deer : 65 %
Accuracy of dog : 53 %
Accuracy of frog : 67 %
Accuracy of horse : 57 %
Accuracy of ship : 80 %
Accuracy of truck : 70 %대체적으로 상승했지만 아직 65%밖에 안되었다..
여러가지 방법들을 찾아봤다. learning rate를 줄여보기도 하고, Epoch을 더 늘려보기도 했다.
하지만 Epoch을 늘려도 어느 시점부터는 오히려 정확도가 떨어졌다.
2. CNN 수정
결국 특징들 (Feature maps)도 늘리고 convolutional layer와 fully connected layer를 하나 늘려보기로 했다.
이때 커널의 크기를 5로 하면 pooling 과정에서 이미지 픽셀이 너무 작아져 사라지기 때문에, padding을 1로 주었다.
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
#out_channel 증가
self.conv1 = nn.Conv2d(3, 16, 5)
self.conv2 = nn.Conv2d(16, 32, 5)
#conv layer도 한 개 추가
self.conv3 = nn.Conv2d(32, 64, 5)
self.pool = nn.MaxPool2d(2, 2, 1)
self.fc1 = nn.Linear(64 * 2 * 2, 192)
#Full-connection layer도 추가
self.fc2 = nn.Linear(192, 128)
self.fc3 = nn.Linear(128, 84)
self.fc4 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 64 * 2 * 2)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = self.fc4(x)
return x
net = Net()
net.to(device)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# CUDA 기기가 존재한다면, 아래 코드가 CUDA 장치를 출력합니다:
print(device)
net = Net()
net.to(device)
#inputs, labels = inputs.to(device), labels.to(device) 로 cuda 사용python[1, 2000] loss: 2.302
[2, 2000] loss: 1.991
...
[19, 2000] loss: 0.447
[20, 2000] loss: 0.418javaAccuracy of the network on the 10000 test images: 70 %
Accuracy of plane : 77 %
Accuracy of car : 87 %
Accuracy of bird : 57 %
Accuracy of cat : 53 %
Accuracy of deer : 48 %
Accuracy of dog : 56 %
Accuracy of frog : 73 %
Accuracy of horse : 77 %
Accuracy of ship : 82 %
Accuracy of truck : 82 %Epoch을 20회 더 늘려서 총 40회로 진행해보았다. loss는 확실히 더 줄어들었는데 결과는 오히려 안좋아졌다.
[1, 2000] loss: 0.392
[2, 2000] loss: 0.371
...
[19, 2000] loss: 0.130
[20, 2000] loss: 0.119
Finished TrainingjavaAccuracy of the network on the 10000 test images: 69 %
Accuracy of plane : 75 %
Accuracy of car : 80 %
Accuracy of bird : 60 %
Accuracy of cat : 54 %
Accuracy of deer : 64 %
Accuracy of dog : 58 %
Accuracy of frog : 73 %
Accuracy of horse : 67 %
Accuracy of ship : 78 %
Accuracy of truck : 76 %
3. Dropout
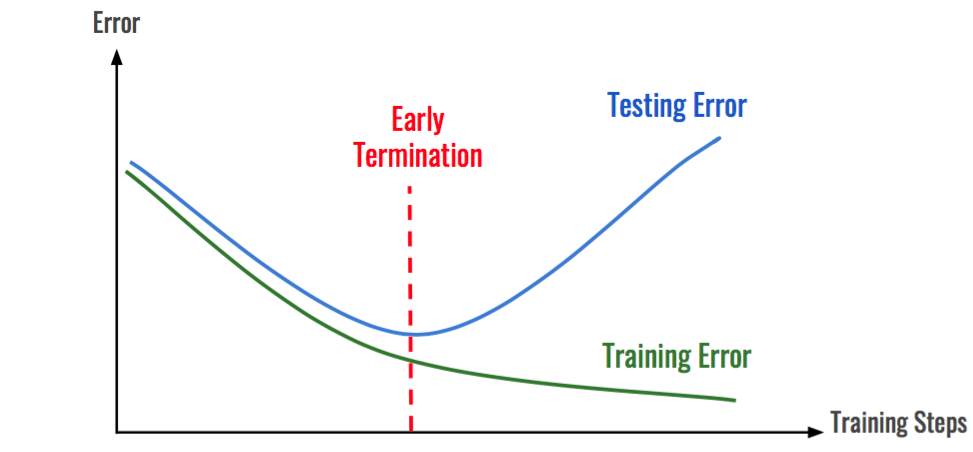
위와 같은 과적합이 발생했을 때 사용할 수 있는 간단한 방법 중 하나가 Dropout 방법이다.

Dropout은 네트워크의 일부를 생략하는 것으로, 일부 노드를 빼고 학습을 진행하여 생략한 네트워크는 영향을 끼치지 않게 하는 것이다.
이렇게 하면 학습이 너무 입력 데이터에만 의존하는 정도가 좀 덜해짐으로 과적합을 줄일 수 있다.
물론 테스트할때는 Dropout을 하면 안된다.
Dropout을 적용하는 순서는 대체로 ReLU등의 Activation 함수 적용 이후, Pooling 이전일때가 가장 적절하다고 한다.
[Convolution - Batch Normalization - Activation - Dropout - Pooling]
0.5만큼 (절반을 꺼버림) Dropout을 합성곱층에서 제일 마지막에, 완젼연결층에서 처음에 적용시키고 진행해보니, 미약한 발전이 있었다.
self.dropout1 = nn.Dropout(p=0.5, inplace=False)
x = F.relu(self.conv3(x))
x = self.dropout1(x)
x = self.pool(x)
x = x.view(-1, 64 * 2 * 2)
x = F.relu(self.fc1(x))
x = self.dropout1(x)Accuracy of the network on the 10000 test images: 71 %
Accuracy of plane : 73 %
Accuracy of car : 88 %
Accuracy of bird : 62 %
Accuracy of cat : 50 %
Accuracy of deer : 59 %
Accuracy of dog : 58 %
Accuracy of frog : 78 %
Accuracy of horse : 77 %
Accuracy of ship : 82 %
Accuracy of truck : 80 %
여기서 다시 채널 수를 모든 합성곱층에서 두배로 늘리고 Epoch을 40회 진행하였다.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 5)
self.conv2 = nn.Conv2d(32, 64, 5)
self.conv3 = nn.Conv2d(64, 128, 5)
self.pool = nn.MaxPool2d(2, 2, 1)
self.fc1 = nn.Linear(128 * 2 * 2, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, 84)
self.fc4 = nn.Linear(84, 10)
self.dropout1 = nn.Dropout(p=0.5, inplace=False)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(x)
x = F.relu(self.conv2(x))
x = self.pool(x)
x = F.relu(self.conv3(x))
x = self.dropout1(x)
x = self.pool(x)
x = x.view(-1, 128 * 2 * 2)
x = F.relu(self.fc1(x))
x = self.dropout1(x)
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = self.fc4(x)
return x[1, 2000] loss: 2.303
[2, 2000] loss: 2.144
...
[39, 2000] loss: 0.280
[40, 2000] loss: 0.263
Finished Trainingjava아슬아슬하지만 기존의 목표였던 70% 이상이 나와서 일단은 만족이다..
Accuracy of the network on the 10000 test images: 74 %
Accuracy of plane : 78 %
Accuracy of car : 85 %
Accuracy of bird : 58 %
Accuracy of cat : 60 %
Accuracy of deer : 66 %
Accuracy of dog : 64 %
Accuracy of frog : 82 %
Accuracy of horse : 78 %
Accuracy of ship : 85 %
Accuracy of truck : 84 %
'코딩 > 이미지 분류 [PyTorch]' 카테고리의 다른 글
| Flask를 이용하여 파이토치를 REST API로 베포하기 (0) | 2020.11.02 |
|---|---|
| REST API란? [특징, 규칙] (0) | 2020.11.02 |
| 머신러닝 : CNN (합성곱신경망) [Convolution, Pooling] (0) | 2020.10.06 |
| 머신러닝 : 파이토치로 사진 분류하기 [CIFAR-10 CLASSIFIER] (2) | 2020.10.05 |
| 머신러닝 : 파이토치 시작하기 [Tensor 생성, 덧셈, CUDA] (0) | 2020.10.04 |
Comment