
1. 1. 데이터 셋 불러오고 정규화하기
2. 2. CNN 정의하기
3. 3. Loss와 Optimizer 정의하기
4. 4. 학습하기
5. 5. 테스트하기

본 게시글은 PyTorch 공식 홈페이지의 "파이토치로 딥러닝하기 : 60분만에 끝장내기"를 진행하면서 작성한 글입니다!
머신 러닝을 하기 위해, 이미지, 텍스트, 오디오, 비디오 등의 데이터를 사용할 때 numpy 배열로 데이터를 로드할 수 있다.
그리고 이 numpy 배열을 Torch.*Tensor로 변환해 Pytorch에서 사용할 수 있다.
이번에 도전해볼 CIFA-10에서의 예제는 R,G,B 3채널의 32*32 크기의 이미지들로
‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’의 클래스가 섞여있다.
이제 이 10가지 클래스의 사진들을 분류할 수 있도록 학습하는 것이 목표이다.
이러한 데이터 셋을 torchvision 패키지를 통해 전처리 작업을 간단하게 진행할 수 있다고 하는데, torchvision.datasets와torch.utils.data.DataLoader가 있다고 한다. 아직 잘 모르겠으니 예제를 진행하면서 알아보자.
이미지 분류기 (Image classifier)를 학습하는 과정은 다음과 같다.
- torchvision을 사용하여 CIFA training, test 데이터 셋을 불러오고 정규화시키기
- CNN (Convolutional Neural Network) 정의하기
- Loss와 Optimizer 정의하기
- Training 데이터로 학습시키기
- Test 데이터로 테스트해보기
하나씩 직접 해보면서 생각해보자.
1. 1. 데이터 셋 불러오고 정규화하기
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
#데이터 불러오기, 학습여부 o
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
#학습용 셋은 섞어서 뽑기
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
#데이터 불러오기, 학습여부 x
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
#테스트 셋은 굳이 섞을 필요가 없음
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
#클래스들
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')앞서 말한 torchvision을 사용하면 CIFAR-10 데이터들을 간단하게 불러올 수 있다고 한다.
이때 'batch_size'는 한번에 몇 개씩 학습 할 것인지, 'shuffle'은 데이터를 섞어서 (랜덤하게) 뽑을것인지이다
num_workers는 데이터 로딩을 위해 몇개의 서브 프로세스를 사용할 지라는데, 보통 코어의 절반정도라고 한다...(잘모름)
튜토리얼에선 만약 에러가 발생하면 0으로 바꾸라고 한다
https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader
원래 이미지는 R,G,B 채널마다 0~255사이의 값인데 torchvision으로 불러오는 데이터셋은 0~1 범위의 PILImage이다.
이러한 이미지를 -1~1범위로 사용하기 위해 Tensor로 정규화시켜준다 (평균 : 0.5, 표준편차 : 0.5)
데이터 셋들을 전부 정규화시켜줌으로써 학습하기 전 공평하게 준비를 하는 것이다.
잘 가져왔나 이미지를 확인해보자.
import matplotlib.pyplot as plt
import numpy as np
#이미지 확인하기
def imshow(img):
img = img / 2 + 0.5 # 정규화 해제
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 학습용 이미지 뽑기
dataiter = iter(trainloader)
images, labels = dataiter.next()
# 이미지 보여주기
imshow(torchvision.utils.make_grid(images))
# 이미지별 라벨 (클래스) 보여주기
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
아까 batch_size가 4였기 때문에, 한번에 4개씩 뽑아와 학습한다. 그래서 이미지도 4개씩 나온다.
또 shuffle을 사용해서, 누를때마다 랜덤으로 4개씩 나온다.
2. 2. CNN 정의하기
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
#input = 3, output = 6, kernal = 5
self.conv1 = nn.Conv2d(3, 6, 5)
#kernal = 2, stride = 2, padding = 0 (default)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
#input feature, output feature
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
# 값 계산
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()여기서 __ init __(self)는 생성자로, 생성됨과 동시에 함수를 정의한다.
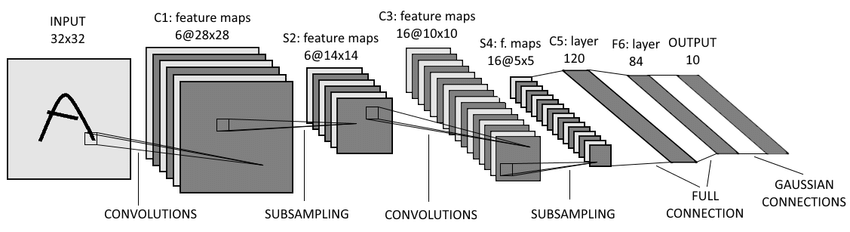
CNN에 대해서 간단하게 설명하자면, 이전까지 사용되던 Fully Connected Layer는 3차원 데이터를 input으로 넣기 위해 1차원의 평평한 데이터로 펼쳐서 넣었는데 (ex) [28,28,1] -> 28 * 28 * 1) 이러지 말고, 데이터의 3차원 형상을 살리면서 학습하게 만든 모델이 CNN이다. (Convolutional Neural Network)
대표적인 CNN 알고리즘 중 LeNet-5는 아래와 같은 과정을 거친다.
3. 3. Loss와 Optimizer 정의하기
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)pythoncriterion은 Loss, 즉 손실함수를 정하는 부분이다.
손실함수는 실제값과 예측값에 대한 차이, 한마디로 얼마나 틀리게 생각했냐라는 뜻인데,
가장 쉬운 예로는 평균제곱오차(MSE)가 있다. 12∑n(예측값−실제값)2
여기서 사용한 방법은 교차 엔트로피 오차(Cross Entropy Error (CEE))이다. −∑ni=1실제값ilog예측값i
optimizer에 대해서 말하기 이전에 학습이란 과연 무엇일까. 이번 예제에서는 사진을 잘 분류하는 것이다.
뉴런에서 데이터를 입력받으면, 나름의 알고리즘으로 잘 만지작거려서 출력하는데,같은 알고리즘에서도 가중치에 따라 결과가 달라지게 된다.
그렇다면 우리는 사진을 잘 분류하기 -> 사진을 분류할때 에러를 줄이기 -> 에러를 줄이기 위해 가중치를 조절하기의 과정으로 학습을 생각할 수 있다.
이러한 가중치를 조절할때 사용되는 것이 learning rate와 gradient이다.
gradient는 기울기, 즉 에러를 줄이려면 -> 에러의 그래프에서 기울기가 작은쪽으로이다. 수도꼭지로 생각하면 물을 뜨거운물로 틀것이냐 찬물로 틀것이냐가 된다.
learning rate는 양, 한번에 얼마씩 바꿀 것인가이다. 수도꼭지에서 물을 얼마나 세게 틀것이냐이다.
다시 돌아와서 이러한 gradient와 learning rate를 조절하는 방법들이 optimizer이다.
여기서 SGD방식은 매번 실행할 때 마다 기울기를 계산해서 바꾸는 게 아니라 확률적(Stochastic)으로 선택된 부분마다 바꾸는 방법이다.
여기서 momentum까지 줬는데 관성 즉 이전 방향을 참고하여 같은 방향으로 일정한 비율만 수정하게 하는 방법이다.
위 두 방법 모두 기울기의 수정이 한도끝도없이 지그재그 (- -> + -> -)로 바뀌는 것을 줄여준다.
4. 4. 학습하기
for epoch in range(2): #데이터셋 2번 받기
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 입력 받기 (데이터 [입력, 라벨(정답)]으로 이루어짐)
inputs, labels = data
#학습
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 결과 출력
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000개마다
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
#여기에 학습한 모델 저장
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)python[1, 2000] loss: 2.215
[1, 4000] loss: 1.974
[1, 6000] loss: 1.716
[1, 8000] loss: 1.607
[1, 10000] loss: 1.564
[1, 12000] loss: 1.501
[2, 2000] loss: 1.434
[2, 4000] loss: 1.381
[2, 6000] loss: 1.365
[2, 8000] loss: 1.344
[2, 10000] loss: 1.313
[2, 12000] loss: 1.322
Finished TrainingjavaEpoch은 전체 사이클 (전체데이터)을 몇번 반복 할 것인가다. 당연히 적으면 많이 틀리고, 또 너무 많으면 과적합 문제가 발생한다.
과적합은 너무 훈련 데이터에만 치중해버린 문제이다. 너무 훈련 데이터에만 최적화가 되어버려 테스트 데이터에서는 이상한 결과가 나와버리게 된다.
#optimizer의 기울기를 0으로 만들기 (변화도가 누적되지 않게 하기 위해)
optimizer.zero_grad()
# output 구하기
outputs = net(inputs)
# loss 계산
loss = criterion(outputs, labels)
#backpropagation (기울기 계산)
loss.backward()
#업데이트
optimizer.step()python위의 학습과정은 자주 사용되는 방법인것 같다. 실제로 기울기를 측정하기 위한 backpropagation과정은 여러 단계를 계속해서 미분해야 하기 때문에 구현하고자하면 복잡하다. 하지만 pytorch 등의 라이브러리의 가장 큰 장점이 알아서 해준다는 것이다.
5. 5. 테스트하기
2번 사이클을 돌았는데, 그럼 신경망이 잘 학습했는지 결과를 확인해보자.
dataiter = iter(testloader)
images, labels = dataiter.next()
# 실험용 데이터와 결과 출력
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
# 학습한 모델로 예측값 뽑아보기
net = Net()
net.load_state_dict(torch.load(PATH))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))
3개맞았다. 한번 전체 데이터셋으로도 해보자
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))Accuracy of plane : 32 %
Accuracy of car : 73 %
Accuracy of bird : 50 %
Accuracy of cat : 38 %
Accuracy of deer : 44 %
Accuracy of dog : 33 %
Accuracy of frog : 63 %
Accuracy of horse : 48 %
Accuracy of ship : 89 %
Accuracy of truck : 58 %대략 이정도의 정답이 나왔다. GPU로도 하는 법이 있지만 GPU가 안되기 때문에 생략.
그렇다면 다음에는 정답률을 높혀보자....
'코딩 > 이미지 분류 [PyTorch]' 카테고리의 다른 글
| Flask를 이용하여 파이토치를 REST API로 베포하기 (0) | 2020.11.02 |
|---|---|
| REST API란? [특징, 규칙] (0) | 2020.11.02 |
| 머신러닝 : CIFAR-10 성능향상 [Conv, Linear, Dropout] (2) | 2020.10.07 |
| 머신러닝 : CNN (합성곱신경망) [Convolution, Pooling] (0) | 2020.10.06 |
| 머신러닝 : 파이토치 시작하기 [Tensor 생성, 덧셈, CUDA] (0) | 2020.10.04 |
Comment