
1. 문제
2. 풀이
3. 결과

1. 문제
문제 링크 : https://programmers.co.kr/learn/courses/30/lessons/42576/
코딩테스트 연습 - 완주하지 못한 선수
수많은 마라톤 선수들이 마라톤에 참여하였습니다. 단 한 명의 선수를 제외하고는 모든 선수가 마라톤을 완주하였습니다. 마라톤에 참여한 선수들의 이름이 담긴 배열 participant와 완주한 선수��
programmers.co.kr
수많은 마라톤 선수들이 마라톤에 참여하였습니다. 단 한 명의 선수를 제외하고는 모든 선수가 마라톤을 완주하였습니다.
마라톤에 참여한 선수들의 이름이 담긴 배열 participant와 완주한 선수들의 이름이 담긴 배열 completion이 주어질 때, 완주하지 못한 선수의 이름을 return 하도록 solution 함수를 작성해주세요.
제한사항
- 마라톤 경기에 참여한 선수의 수는 1명 이상 100,000명 이하입니다.
- completion의 길이는 participant의 길이보다 1 작습니다.
- 참가자의 이름은 1개 이상 20개 이하의 알파벳 소문자로 이루어져 있습니다.
- 참가자 중에는 동명이인이 있을 수 있습니다.
입출력 예
| participant | completion | return |
|---|---|---|
| [leo, kiki, eden] | [eden, kiki] | leo |
| [marina, josipa, nikola, vinko, filipa] | [josipa, filipa, marina, nikola] | vinko |
| [mislav, stanko, mislav, ana] | [stanko, ana, mislav] | mislav |
2. 풀이
단순하게 문자열을 비교하는 방식으로 했는데, 당연히 효율성에서 시간초과를 맞았다.
최대 20자리의 이름들이니 두 문자열을 비교하는데 20, 배열 두개를 For문으로 돌리니 O(20N2)의 시간복잡도였다.
나만의 비교 메소드를 만들어도 봤으나 시간초과의 늪을 벗어나지 못하여, 문자열 해시를 생각해 보았다.
알고리즘 스터디 탐색 파트에서 나온 호너의 방법대로((u0g+u1)g)+u2...+un−2)g+un−1 를 이용하여 문자열을 해싱 한 다음 해시값을 비교함으로 도전했다.
시간이 다소 단축되었으나, 시간초과임은 분명했다. 어차피 문자열을 해싱한 값끼리 비교하기 때문에 비교 자체는 빨라도, 2중For문을 돌아야 하는것은 똑같고, 각각의 문자열을 해싱하는데 걸리는 복잡도까지 생각하면O(20N2) 로 같다.
class Solution {
public String solution(String[] participant, String[] completion) {
String answer="";
boolean find = false;
int temp;
int[] completionHash = new int[completion.length];
int[] completionHashVisited = new int[completion.length];
//해시함수화
for(int i=0; i<completion.length; i++) {
completionHash[i] = StringHashing(completion[i]);
}
for(int i=0; i<participant.length; i++) {
temp = StringHashing(participant[i]);
//System.out.println(temp);
for(int j=0; j<completion.length; j++) {
if(temp == completionHash[j] && completionHashVisited[j] != 1) {
find = true;
//중복된 이름 체크
completionHashVisited[j] = 1;
break;
}
}
//찾으면 바로 멈추게
if(!find) {
return participant[i];
}
find = false;
}
return answer;
}
public int StringHashing(String s) {
int p = 31; //보통 소문자면 31, 대,소문자면 53 (문자열에 입력할 수 있는 문자의 개수)
//long m = 2147483647; //큰 소수중에 하나(충돌 안나게)
int hash = 0;
int pow = 1; //패딩
for(int i=0; i<s.length(); i++) {
hash = (hash + (s.charAt(i) - 'a' +1) * pow); //% m;
pow = (p*pow); //% m;
}
return (int) hash;
}
}java밑져야 본전이겠다는 마인드로 그냥 두 배열을 각각 라이브러리로 정렬시키고 비교한다면
A B B D E / A B D E 이런 식으로 다른 값이 바로 찾아지지 않을까 해서 시도했는데 통과되었다.
자바 기본함수로 문자열을 정렬하는 방법을 정확히 몰라 어느정도의 복잡도인지는 모르겠으나, 20글자를 그냥 비교한다고 생각했을때 정렬 + 비교까지 해서 O(20nlgn+n) 이 정도라고 생각한다.
import java.util.Arrays;
class Solution {
public String solution(String[] participant, String[] completion) {
Arrays.sort(participant);
Arrays.sort(completion);
int i=0;
for(i=0; i<completion.length; i++) {
if(!Compare(participant[i],completion[i])) {
return participant[i];
}
}
return participant[i];
}
public boolean Compare(String a, String b) {
//System.out.println(a + " " + b);
if(a.length() != b.length()) return false;
for(int i=0; i<a.length(); i++) {
if(a.charAt(i) - b.charAt(i) != 0) return false;
}
return true;
}
}java다른 사람의 풀이를 봤는데, 해시 함수를 이용해서 매우 간결하게 푼 풀이가 있었다. 참가자 배열에서 getOrDefault(player,0) 을 통해 중복까지 체크해주면서 키에 따른 값들을 1 , 1 , 2 .. 등등으로 넣어주고, 동일하게 완주자 배열에서 -1씩 하면서 결국 키가 0인 값을 찾아내는 방식이다.
알고리즘을 몇개월 째 공부하고 있지만 여전히 자료구조는 배열, 스택, 큐에서 벗어나지 못하고 있었는데 tree나 set, hashmap등도 많이 다뤄봐야겠다고 느꼈다.
import java.util.HashMap;
class Solution {
public String solution(String[] participant, String[] completion) {
String answer = "";
HashMap<String, Integer> hm = new HashMap<>();
for (String player : participant) hm.put(player, hm.getOrDefault(player, 0) + 1);
for (String player : completion) hm.put(player, hm.get(player) - 1);
for (String key : hm.keySet()) {
if (hm.get(key) != 0){
answer = key;
}
}
return answer;
}
}java
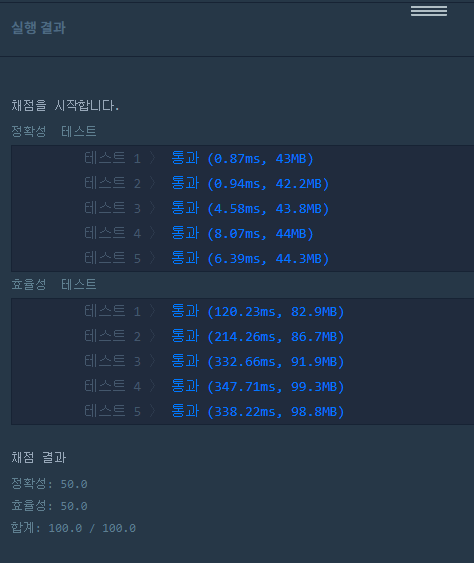
3. 결과
'알고리즘 > 문제풀이' 카테고리의 다른 글
| 위장 (프로그래머스) [JAVA] (0) | 2020.09.08 |
|---|---|
| 입국심사 (프로그래머스) [JAVA] (0) | 2020.09.05 |
| K번째 수 (프로그래머스) [JAVA] (0) | 2020.08.26 |
| H-Index (프로그래머스) [JAVA] (0) | 2020.08.26 |
| 정수 삼각형 (프로그래머스) [JAVA] (0) | 2020.08.18 |
Comment