

선형탐색
순서대로 하나 하나씩 찾는 방법. $O(N)$의 시간복잡도.
public int LinearSearch(int data[], int key){
for(int i=0; i<data.length; i++){
if(data[i] == key) return i;
}
return -1;
}
이진탐색
미리 정렬되어 있는 자료에서 가능. Up Down 게임과같다.
중간 값을 선택한 뒤, 크면 오른쪽으로 작으면 왼쪽으로 반 씩 나눠가면서 탐색.
$O(lgN)$의 시간복잡도

public int BinarySearch(int data[], int key){
int max = data.length-1;
int min = 0;
int i = 0;
while(min <= max) {
i = (min+max)/2;
if(data[i] == key) return i;
else if(data[i] < key){
min = i+1;
}
else if(a[i] > key){
max = i-1;
}
}
return -1;
}
//라이브러리
Arrays.binarySearch(data,key);
이진탐색트리
BST는 이진 탐색 트리 (binary search tree)로 이진 탐색과 유사한 방법으로 트리 구조를 이용한 형태이다.
왼쪽 서브트리의 키값은 루트보다 작고, 오른쪽 서브트리의 키값은 루트보다 큰 형태로
매 노드별 key값과 비교하는 방법이다.

//BST 탐색
public int BianrySearchTree(int key) {
// 트리가 비었을 때
if (root == null) return -1;
Node focusNode = root;
while (focusNode.key != key) {
if (key < focusNode.key) {
focusNode = focusNode.leftChild;
} else {
focusNode = focusNode.rightChild;
}
//노드가 없을 때
if (focusNode == null)
return -1;
}
return focusNode.data;
}노드를 삽입시에도 탐색 연산을 수행하고, 탐색이 종료된 위치에 새로운 노드를 삽입한다.
삭제 연산시에는 leaf노드인 경우 단순히 삭제하면 되지만, 자식 노드가 2개인 경우 삭제할 노드를 대체할 노드를 자식 중에 찾아내어 대체시키는 방법이 있다.
해시탐색
해시는 미리 데이터와 저장한 곳의 주소를 미리 연결함으로써 짧은 시간에 탐색할 수 있게 만든 알고리즘.
이를 위해서는 데이터를 해시 함수를 통해 주소로 변환시켜야 한다.
이때 해시 테이블의 주소로 변환하는 해시함수가 잘 설계되어야만 탐색의 효율이 증대될 수 있다. 좋은 해시 함수의 조건은 다음과 같다.
- 충돌이 적어야 한다.
- 해시함수 갑싱 해시 테이블의 주소 영역 내에서 고르게 분포되어야 한다.
- 계산이 빨라야 한다.
제산 함수는 나머지 연산자를 사용하여 탐색 키를 해시 테이블의 크기로 나눈 나머지를 해시 주소로 사용하는 방법이다.
$h(k) = k$ $mod M$ ex) 4772 mod 13 = 1, 8657 mod 13 = 12
public int Hashfunction(int data[], int table[]){
int range = table.length;
for(int i=0; i<data.length; i++){
table[data[i] % range] = data[i];
}
}
public int findData(int key, int table){
return table[key % table.length];
}폴딩 함수는 탐색 키를 여러 부분으로 나누어 모두 더한 값을 해시 주소로 사용한다.
탐색 키를 나누고 더하는 방법에는 이동 폴딩(shift folding)과 경계 폴딩(boundary folding)이 대표적이다.
이동 폴딩은 탐색키를 여러 부분으로 나눈 값들을 더해서 해시 주소로 사용하고
경계 폴딩은 탐색 키의 이웃한 부분을 거꾸로 더해서 해시 주소를 만든다.

주로 탐색 키가 해시 테이블의 크기보다 큰 정수일때 사용된다.
32비트 탐색 키 -> 테이블은 16비트 정수일 때 앞의 16비트만 다르고 뒤의 16비트는 같은 탐색 키인 경우 충돌이 발생
탐색 키를 몇 개의 부분으로 나누어 더하거나 , xor 연산 => 폴딩이라고 한다.
탐색 키가 문자열일 경우 주의할 점.
가장 보편적인 방법은 아스키 코드 값을 모두 더하는 것 but 탐색 키들이 동일한 문자로 이루어져있지만 위치가 다른 경우 ex) are, ear 같은 경우 구분할 수 없다.
아스키 문자 코드가 65~122이기 때문에, 3자리인 경우 195~366으로 해시 주소가 집중될 수 있다.
이를 해결하기 위해 아스키 코드 x 문자의 위치를 사용한다.
문자열 s가 n개의 문자이고, i번째 문자의 값을 $u_i$라 할때 $u_0g^{n-1} +u_1g^{n-2} + ... + u_{n-2}g + u_{n-1}$로 계산
호너의 방법을 사용하여 $((u_0g + u_1)g)+u_2 ... +u_{n-2})g + u_{n-1}$ 로 계산할 수 있다.
이때 서로 다른 탐색 키를 갖는 항목들이 같은 해시 주소를 가진 현상이 충돌이라고 한다. 충돌이 발생하면 더 이상 저장할 수 없기 때문에, 빠르게 해결해야 한다.
충돌을 해결하는 방법으로는 주로 아래 두 가지 방법이 있다. (물론 더 다양하다)
충돌이 일어난 항목을 해시 테이블의 다른 위치에 저장하기 (선형 조사법, 이차 조사법, 이중 해시법)
해시 테이블의 하나의 위치가 여러 개 항목을 저장할 수 있도록 해시 테이블의 구조를 변경하기. (체이닝)
선형 조사법은 충돌 발생 시 해시 테이블에서 비어 있는 공간을 찾는 방법이다.
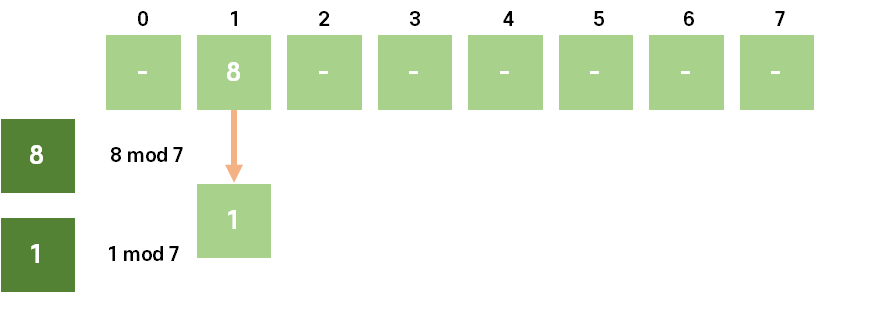
위의 제산 함수의 예시로는 h(k)에서 충돌이 일어나면 h(k)+1, h(k)+2로 찾는 방법이다
ex) 8 mod 7 = 1, 1 mod 7 = 1 -> 1+1 mod 7 = 2
하지만 이럴때, 탐색 키들이 결국엔 집중되어 저장되는 군집화 현상이 발생되고, 결합까지 발생할 수 있어서 더 나은 조사법이 필요하다.
이차 조사법(quadratic probing)은 선형 조사법을 발전시킨 형태로, 다음 조사한 위치를 아래의 식에 의하여 결정한다.
$(h(k) + inc^2)mod M $ $for inc = 0,1....M-1$ ex) h(k), h(k)+4, h(k)+9
이중 해시법, 재해싱 (double hashing, rehashing)은 오버플로가 발생 할 때, 원래 해시 함수와 다른 별개의 해시 함수를 이용하는 방법으로, 비교적 균일하게 분포할 수 있다. 해시 함수값이 같더라도 탐색 키가 다르면 서로 다른 조사 순서를 갖기 때문에, 집중을 피할 수 있다.

두번째 해시 함수는 조사 간격을 결정하므로 step = C - (k mod C)로 나타낼 수 있으며,
충돌 발생시엔 h(k), h(k)+step h(k)+2 * step으로 조사된다.
ex) h(k) = k mod7과 h2(k) = 5 - (k mod 5)일때
h(8) = 8 mod7 = 1
h(1) = 1 mod 7 = 1 (충돌) = (h(1) + h2(1)) mod 7 = (1+5 - (1mod5)) mod7 = 5
이때 반드시 해시 테이블의 크기는 소수여야 한다. 만약 소수가 아니면, 테이블의 모든 인덱스를 조사할 수 없게 된다.
선형 조사법은 시간이 많이 소요되는데, 해시 주소가 다른 탐색키하고도 비교해야 하기 때문이다. 그에 비해 체이닝은 오버플로 문제를 각 인덱스에 삽입과 삭제가 용이한 연결 리스트를 할당함으로써 충돌을 처리한다.
ex) h(8) = 8 mod7 = 1
h(1) = 1 mod 7 = 1 (충돌) = 8 - 1로 연결
가장 이상적인 해싱의 시간 복잡도는 O(1)이다. 해시 함수를 한번만 계산하면 되기 때문이다. 하지만 충돌이 발생하기 때문에 이보다 느려지게 된다. 해시 테이블이 얼마나 채워져 있는지를 나타내는 척도인 적재 밀도(loading density) or 적재 비율을 정의하여 해싱의 성능을 분석해야 한다
항목 n개와 테이블의 크기 M일때 적재 밀도$a$ = $\frac{저장된 항목의 개수}{해싱 테이블의 버켓의 개수} = \frac{n}{M}$ 으로 표현할 수 있다.
이때 실패한 탐색의 비교 연산의 개수는 $\frac{1}{2}(1 + \frac{1}{{1-a}^2})$, 성공한 탐색은 $\frac{1}{2}(1 + \frac{1}{{1-a}})$로 도출된다.
각 알고리즘에 따라 적재 밀도, 해시 함수, 오버 플로 해결 방법으로 해싱의 성능을 평가한 결과들을 찾아보고 최적화된 해시 함수를 선택한다면, 이진 탐색보다 해싱이 빠르고 삽입이 용이하기 때문에 훨씬 효율적으로 사용할 수 있을 것이다.
참고 : [C언어로 쉽게 풀어 쓴 자료구조 - 천인국]
'알고리즘 > 스터디' 카테고리의 다른 글
| 10. 순열과 조합 [JAVA] (0) | 2020.09.02 |
|---|---|
| 9. 최대, 최소 찾기 (순차, 토너먼트, 선택 알고리즘) (0) | 2020.09.01 |
| 7. 정렬 (2) - 합병 정렬, 힙 정렬, 쉘 정렬 (0) | 2020.08.18 |
| 6. 정렬 (1) - 삽입 정렬, 버블 정렬, 퀵 정렬 (0) | 2020.08.12 |
| 5. 재귀 호출 - 완전 탐색, 동적 프로그래밍 (0) | 2020.07.31 |
Comment