
1. 운영체제(Operating System)
2. Windows
3. UNIX
4. 기억장치
5. 가상기억장치 (Virtual Memory)
6. 페이지 교체 알고리즘
7. 페이징 기타 관리사항
8. 프로세스 (Process)

1. 운영체제(Operating System)
컴퓨터 시스템의 자원을 효율적으로 관리하고, 사용자가 컴퓨터(하드웨어)를 편하게 사용할 수 있도록 환경을 제공하는 소프트웨어. (사용자와 하드웨어 간 인터페이스)
운영체제 목적
| 목적 | 의미 |
|---|---|
| 처리 능력 | 일정 시간 내에 처리하는 일의 양 |
| 반환 시간 | 시스템에게 작업을 의뢰한 시간부터 처리가 완료될 때까지 걸린 시간 |
| 사용 가능도 | 필요성에 따라 즉시 사용 가능한 정도 |
| 신뢰도 | 주어진 문제를 시스템이 정확하게 해결하는 정도 |
운영체제 기능
운영체제의 기능은 크게 두가지로 나뉜다.
Extended machine (시스템 호출로 편리한 인터페이스 제공)
Resource machine (여러 프로그램이 경쟁할때 조정)
- 프로세스 스케줄링, 동기화, 생성-제거. 시작-정지, 메시지 전달 관리
- 기억장치(메인 메모리)에서 프로세스에게 메모리 할당, 회수 관리
- 입출력장치 스케줄링, 관리
- 파일 시스템의 생성, 삭제, 변경, 유지 관리
+ 시스템 하드웨어, 네트워크 관리, 제어. 시스템의 오류 검사, 복구
운영체제 종류
| OS | 특징 | 인터페이스 |
|---|---|---|
| Windows | 마이크로소프트에서 개발 | GUI |
| UNIX | AT&T벨, MIT, GE에서 공동 개발한 운영체제 | CLI |
| LINUX | UNIX 기반으로 토발즈가 개발 | CLI |
| MacOS | 애플에서 UNIX 기반으로 개발 | GUI |
| MS-DOS | Windows 이전 OS | GUI |
Windows, MacOS, MS-DOS는 주로 개인 사용자, UNIX, LINUX는 주로 서버에 사용됨
GUI : Graphic User Interface, OS에 그래픽 인터페이스를 통해 요청
CLI : Command Line Interface, OS에 문자 명령어를 통해 요청
2. Windows
마이크로소프트사가 개발한 운영체제, 그래픽 사용자 인터페이스 (GUI) 방식 사용.
- 선점형 멀티태스킹 (Preemptive Multi-Tasking)
동시에 여러 프로그램을 실행하는 멀티태스킹을 하면서 운영체제가 각 작업의 CPU 이용 시간을 제어. 문제 발생시 해당 프로그램 강제종료 후 자원 반환 - PnP (Plug and Play)
프린터, 키보드 등의 주변기기 설치시 하드웨어 사용에 필요한 시스템 환경을 OS가 자동으로 구성 - OLE (Object Linking and Embedding)
다른 응용프로그램에서 작성된 객체들을 현재 작성중인 문서에 자유롭게 연결, 삽입, 편집 가능
3. UNIX
AT&T벨, MIT, GE에서 공동 개발한 운영체제. 커맨드라인 인터페이스(CLI) 방식 사용.
시분할 시스템(Time Sharing System)을 위해 설계된 대화식 운영체제.
대부분 C언어로 작성되어 있어 프로세스 간의 호환성이 높음
소스가 공개된 개방형 시스템으로, 여러 다른 OS의 기반이 됨.
다양한 네트워킹 기능을 통해 서버, 통신망 관리용 OS로도 활용됨.

- 커널 (Kernal)
부팅 시 주기억장치에 적재 된 후 상주하면서 실행.
프로그램과 하드웨어 간의 인터페이스를 담당하며, 사용자나 프로그램이 직접 하드웨어를 조작할 수 없게 함.
- 쉘 (Shell)
시스템과 사용자간의 인터페이스 담당. 사용자의 명령어를 인식해 프로그램 호출, 명령 수행하는 해석기
커널과 다르게 무조건 주기억장치에 모두 적재되어있지 않음, 보조기억장치에서 필요에 따라 교체
명령어가 포함된 파일 형태.
파이프라인 가능(여러 명령을 함께 묶어 처리 -> 다른 명령의 입력으로), 입출력 방향 변경 가능.
- 유틸리티 (Utility)
사용자들이 유닉스 시스템을 편리하게 사용하기 위해 개발도니 프로그램 개발도구.
유틸리티를 사용하여 개발된 응용프로그램들 역시 유틸리티.
UNIX에서 프로세스간 통신
프로세스는 시스템 호출(System call)을 통해 커널의 기능 사용
시그널 (Signal) : 간단한 메시지를 이용하여 통신 (초기)
파이프 (Pipe) : A 프로세스의 출력이 B 프로세스의 입력으로 사용 (단방향)
소켓 (Socket) : 프로세스 사이 대화 가능 (양방향)
4. 기억장치
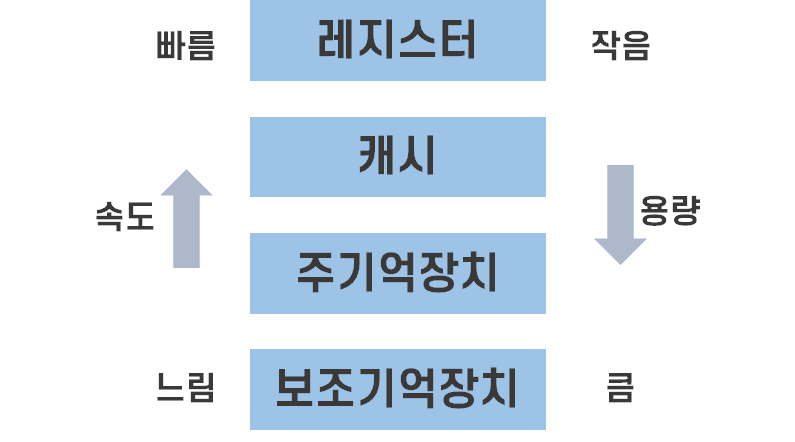
기억장치 관리 전략
[보조기억장치에서 데이터를 주기억장치로 반입 -> 어디에 놓을지 배치 -> 변경시 교체]
1) 반입 (Fetch)
보조기억장치에서 주기억장치로 데이터, 프로그램을 언제 적재할지.
요구 반입 : 참조를 요구할 때 적재 / 예상 반입 : 미리 예상하여 적재
2) 배치 (Placement)
데이터, 프로그램을 주기억장치의 어디에 위치시킬지.
[배치 알고리즘] (4개의 성능은 비슷비슷함)
최초 적합(First fit) : 위에서 부터 탐색하여 제일 먼저 찾은 프로그램보다 큰 영역에 저장
빠르나, 공간낭비가 클 수 있음. 밑에 큰 공간을 안 쓰고 자꾸 위에만 쓰는 문제 발생가능.
최선 적합(Best fit) : 다 검사후 프로그램과 용량이 제일 비슷한 영역에 저장
공간을 절약할 수 있으나, 느림. 딱 맞게 넣다보니 재활용 할 수 없는 아주 작은 공간 발생 가능.
최악 적합(Worst fit) : 다 검사후 프로그램보다 용량이 제일 큰 영역에 저장.
그나마 공간 재활용 가능하나, 반대로 공간 낭비 가능. 느림
다음 적합(Next fit) : 마지막 검색위치를 기억하고, 그 뒤부터 최초 적합 실행
골고루 빈공간을 사용하나 큰 공간을 찾기 힘듦.
3) 교체 (Replacement)
주기억장치가 모두 사용중인 상태에서 새로운 데이터를 배치하려고 할때 어디를 교체할지.
FIFO, OPT, LRU, LFU, NUR, SCR, Clock Page 등 존재.
주기억장치 할당 방법
[연속 할당 기법] (주기억장치에 연속으로 할당)
단일 할당 기법
- 스와핑 : 메모리보다 더 많이 프로그램을 돌리기 위한 기법
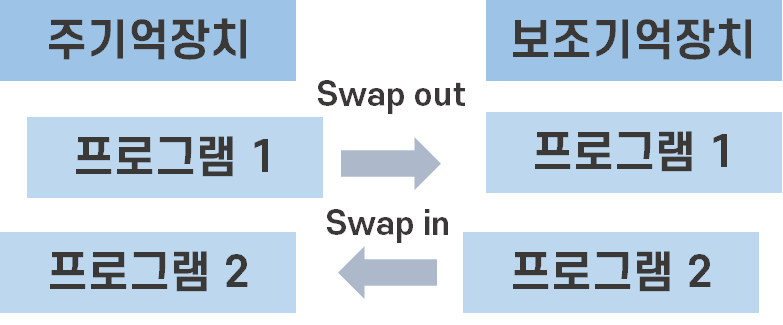
일단 프로그램 전체를 주기억장치에 할당
-> 사용하다 다른 프로그램을 실행하고 싶음
-> 사용하지 않는 프로그램 (Sleep 상태)
-> HDD에 현재 프로그램상태 저장 후 주기억장치에서 내쫓음 (Swap out)
-> 다음 프로그램을 주기억장치로 부름 (Swap in)
(보조기억장치와 주기억장치에 썼다 지웠다하는 비용 지불)
- 오버레이 : 메모리보다 더 큰 프로그램을 돌리기 위한 기법
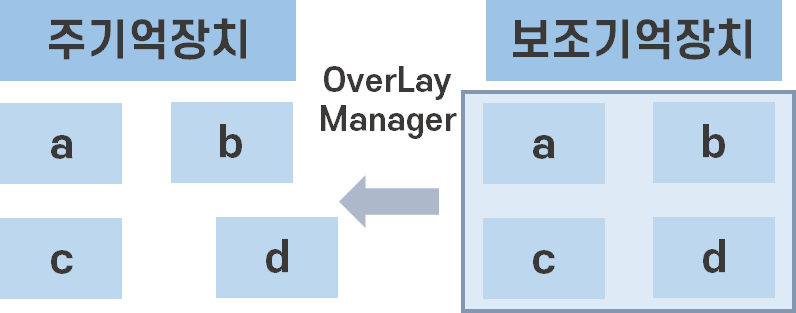
프로그램을 함수단위로 모듈화
-> OverLay Manager가 각각의 기능 별 함수 호출 전 메모리에서 확인
-> 없으면 보조기억장치에서 불러옴 (이 과정에서 이미 메모리에 적재된 함수 쫓아내기도 함)
[다중 분할 할당 기법]
고정 분할 할당 기법
프로그램에 할당하기 전, OS가 주기억장치의 사용자 영역을 고정된 크기로 분할 -> Ready Queue에서 프로그램을 각 영역에서 할당하여 수행
가변 분할 할당 기법
프로그램을 주기억장치에 적재하면서, 필요한 만큼의 크기로 영역을 분할.
문제점
단편화 (Fragmentation)로 인한 메모리 비효율성 발생.
- 내부 단편화 : 파티션 내에서 프로그램이 할당된 후 사용되지 않고 남아있는 공간.
- 외부 단편화 : 파티션 자체가 작아서 프로그램이 할당되지 않고 남아있는 영역.
해결방안
- 병합 (Coalescing) : 끝나면 주변 영역들을 합침
- 압축 (Compaction) : 자투리 메모리 모으기
하지만 부하가 큼 (프로그램을 복사, 붙여넣기) + Optimal한 Algorithm이 매우 어려움.
그래서 가상기억장치 (Virtual Memory) 등장.
5. 가상기억장치 (Virtual Memory)
보조기억장치의 일부를 주기억장치처럼 사용하는 것. (주기억장치가 마치 큰 용량을 가진 것 처럼 사용)
페이징 (Paging)
가상 기억 장치를 페이지 단위로 분할 / 실제 물리적 장치는 프레임 단위로 분할
(페이지 사이즈와 프레임 사이즈는 동일하게)
마치 자기가 모든 가상공간을 다 사용할 수 있다고 생각하면서
-> (페이지번호, 오프셋)을 통해 원하는 데이터 요청
-> OS가 페이지 테이블에서 (페이지번호, 오프셋)을 (프레임 번호, 오프셋)으로 변환
-> 메모리에 없으면 Page Fault 이후 디스크에서 적재 후 교체, 있으면 해당 값을 전달해줌.
이때 프레임 크기에 따른 내부 단편화 발생 가능.
세그멘테이션(Segmentation)
소스 텍스트, 심볼테이블, 상수테이블, 파싱트리, 스택의 논리적인 단위에 따른 세그멘트 생성
위의 세그멘트들의 주소와 오프셋을 통해 접근, 사용 (세그먼트 테이블 사용)
이때 세그멘트의 크기는 가변적임 -> 세그먼트 간 영역 침범을 막기 위한 기억장치 보호키가 필요.
세그멘트에 따른 외부 단편화 발생 가능.
6. 페이지 교체 알고리즘
원하는 페이지가 메인메모리에 없는 Page Fault 발생 시 어느 프레임을 교체할 지 결정해야함.
OPT (Optimal Replacement)
가장 오랫동안 사용하지 않을 페이지를 교체 (모든 미래를 알고 있어야 해서 사실상 불가능)
FIFO (First in First Out)
제일 먼저 적재된 페이지를 기억해뒀다가, 해당 순서대로 교체 (선입선출)
LRU (Least Recently Used)
가장 오랫동안 사용하지 않은 페이지를 교체.
참조된 순서를 기억하기 위해서 SW적으로는 stack 사용, HW상에서는 어려움.
LFU (Least Frequently Used)
사용 빈도가 가장 적은 페이지를 교체.
단순화해서 Reference bit를 사용하는 Second Chance, Clock Page 등의 알고리즘도 존재
NRU (Not Recently Used)
LRU의 구현이 복잡하여 단순화 한 방법.
| CLASS | 참조 (Reference) | 수정 (Modify) |
|---|---|---|
| 0 | X | X |
| 1 | X | O |
| 2 | O | X |
| 3 | O | O |
4가지 클래스 중 교체 우선순위는 0 -> 1 -> 2 -> 3 순 (참조 먼저 확인)
7. 페이징 기타 관리사항
페이지 크기는 보통 CPU 설계자가 결정.
페이지 크기가 클 경우
- 페이지 테이블이 작아져서 매핑속도 빨라짐
- Page fault가 줄어들어 디스크 접근이 줄음 (I/O 시간 줄어듦)
- 하지만 단편화 발생, 주기억장치에 불필요한 적재 늘음, 적재시간 증가
페이지 크기가 작을 경우
- 단편화 줄어듦, 주기억장치에 효율적 적재 (Locality에 일치하게 됨)
- 페이지 테이블이 커져서 매핑속도 느림
- Page fault가 자주 발생 (I/O시간 증가)
Locality
프로세스가 실행되는 동안 주기억장치를 참조할 때 일부 영역을 집중적으로 참조하는 성질이 있다.
Threshing을 방지하기 위한 Working Set의 기반.
- Time Locality
프로세스가 실행되면서 하나의 페이지를 일정 시간 동안 집중적으로 엑세스
반복문, 스택 등을 실행할 때 발생. - Space Locality
프로세스가 실행되면서 하나의 페이지 주변을 집중적으로 엑세스
배열, 순차적 코드 등을 실행할 때 발생.
Working Set
프로세스가 일정 시간 동안 자주 참조하는 페이지들의 집합.
이 워킹셋을 주기억장치에 적재한다면 -> Page Fault가 줄어들어 효율이 높아질 수 있다.
시간이 지날수록 계속 변경됨. Reference bit, Last Used Time 등을 사용함.
Local Page Replacement
프로세스 A의 page fault면 프로세스 A의 working set에서 정책에 따라 교체
각 프로세스별 Working set 추측 후 크기를 잘 할당하는게 중요 (Page fault Frequency로 추측)
Global Page Replacement
프로세스 A의 page fault여도 모든 프로세스의 working set에서 정책에 따라 교체
서로 뺏어오면서 Working Set이 잘 맞춰질 수 있으나, 무한 경쟁 (Threshing) 발생 가능
Free paging
프로그램 실행 초기에는 주기억장치가 비어있기 때문에 무조건 Page Fault 발생.
아예 예상되는 모든 페이지를 적재해놓고 시작해보자는 기법.
Threshing
프로세스의 처리 사간보다 페이지 교체에 소요되는 시간이 더 많아지는 현상.
하나의 프로세스 수행 중 자꾸 page fault가 발생. (전체 프로세스 성능 저하)
적당한 다중 프로그래밍, 워킹 셋 유지, page fault frequency 조절, cpu 지속적 관리 필요
8. 프로세스 (Process)
프로세서(CPU)에 의해 처리되는 프로그램. 실행중인 프로그램, 작업이라고도 함.
운영체제는 프로세스 X, 그냥 코드 형태. (프로세스가 동작 중 해당 코드로 Jump해서 동작)
[다른 형태]
PCB를 가진 프로그램, 실제 기억장치에 저장된 프로그램, 디스패치가 가능한 단위, 프로시저가 활동중인 것, 비동기적 행위(여러 프로세스가 독립적으로 실행)를 일으키는 주체, 운영체제가 관리하는 실행 단위
PCB (Process Control Block, 프로그램 제어 블록)
OS가 프로세스에 대한 정보를 저장해 놓은 곳.
| 정보 | 설명 |
|---|---|
| 프로세스의 현재 상태 | Ready, Wait, Run 등의 프로세스 상태 |
| 포인터 | 부모 프로세스의 주소, 자식 프로세스의 주소 |
| 프로세스 고유 식별자 | 프로세스의 구분을 위한 고유 번호 |
| 스케쥴링, 우선순위 | 스케쥴링 및 프로세스 우선순위 |
| CPU 레지스터 정보 | Accumulator, 인덱스, 범용 레지스터 Program Counter 등 정보 |
| 주기억장치 관리 정보 | 기준 레지스터, Page Table 정보 |
| 입출력 상태 정보 | 입출력장치, 개방 파일 목록 |
| 계정 정보 | CPU 사용 시간, 한정 시간 |
프로세스 상태 전이
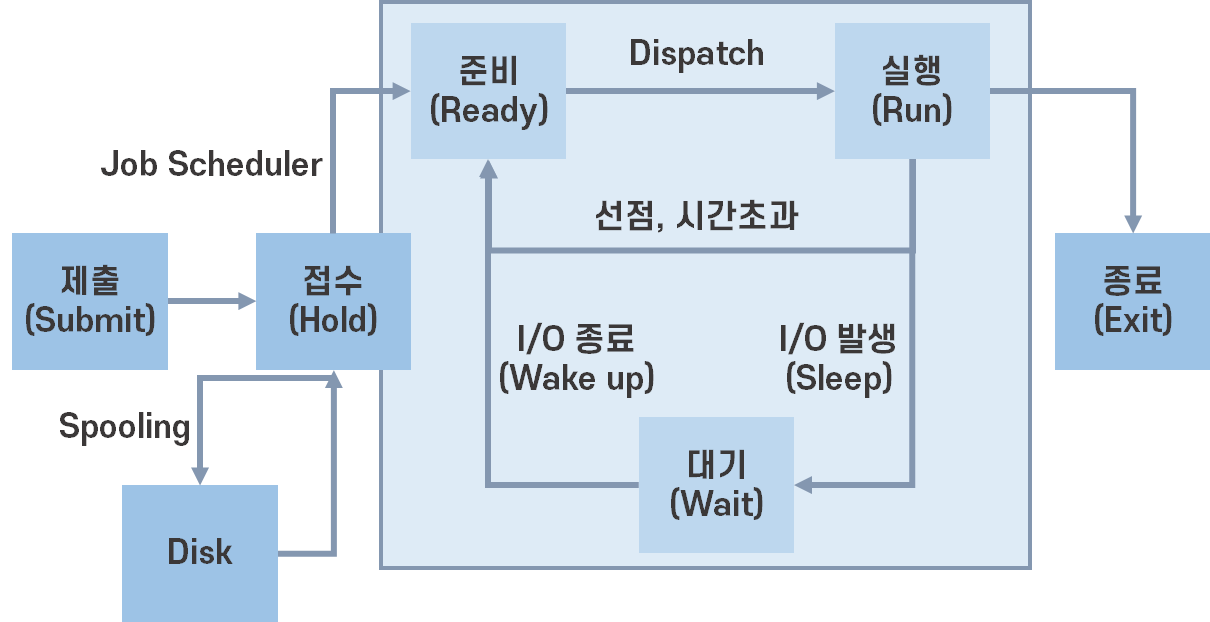
제출(Submit) : 작업을 처리하기 위해 시스템에 작업을 제출
접수(Hold) : 제출된 작업이 디스크의 Spool 공간에 저장된 상태
-> Spooling : 중앙처리장치와 입출력장치의 속도가 차이나서 미리 Spool에 써놓고 한번에 저장하는 기법
준비(Ready) : 프로세스가 프로세서를 할당받기 위해 기다리고 있는 상태
-> Ready Queue에 있는 프로세스들을 Job Scheduler가 순차적으로 실행시킴
실행(Run) : 프로세스가 프로세서를 할당받아 실행되는 상태.
할당 시간이 완료 전에 종료되면 준비 상태로 전이.
실행 도중 I/O가 필요하면 대기상태로 전이
대기(Wait) : I/O가 필요하면 실행중인 프로세스가 중단되고, 완료될 때까지 대기하는 상태
종료(Exit) : 프로세스 실행이 끝나고 할당이 해제된 상태.
(I/O 를 대기하는 동안 cpu가 놀음 -> 여러 프로세스를 실행시키는 멀티 프로그래밍 등장)
스레드 (Thread)
프로세스가 실행되는 하나의 프로그램, 작업이었다면, 스레드는 프로세스 내에서의 실행의 흐름.
프로세스 안에서의 작업 단위로 시스템의 자원을 할당받아 실행됨.
웹브라우저 같이 하나의 프로세스 내에서 여러 동작이 필요한 경우 -> 여러 스레드 사용.
프로세스는 각자 코드, 데이터, 힙, 스택이 구분됨 (서로 다른 프로그램이므로)
하지만 스레드는 프로세스의 데이터, 코드, 힙 동유. (스택, Register State, Program Counter는 따로)
User Thread는 사용자 라이브러리로 사용하여 운용, 구현이 복잡
Kernel Thread는 운영체제의 커널에 의해 운용, 구현 쉬우나 비용이 많이 발생 (프로세스급)
스케쥴링 (Scheduling)
프로세스가 생성되어 실행될 때 필요한 시스템의 자원을 프로세스들에게 할당하는 작업.
주로 CPU를 할당하는데, 현재 할당된 프로세스의 상태 정보를 저장하고, 새로운 프로세스의 상태 정보를 설정한 후 CPU를 할당하는 작업을 문맥 교환이라 함.
스케쥴링이 자주 일어나면 효율이 떨어짐, 하지만 드물게 발생하면 응답성이 떨어짐.
스케쥴링의 목적
공정성, 처리율 증가, CPU 이용률 증가, 우선순위 제도 유지, 오버헤드 최소화, 반응 시간 최소화, 반환 시간 최소화, 대기 시간 최소화(Ready Queue에서), 무한 연기 회피, 균형 있는 자원 사용.
스케줄링 기법
- 비선점 스케줄링 (Non-preemptive)
이미 CPU가 할당되면, 다른 프로세스가 강제로 빼앗아 사용할 수 없음.
프로세스 응답 시간 예측이 쉽고, 일괄적으로 처리하는 방식에 적합함.
중요한 작업이, 상대적으로 덜 중요한 작업을 기다리는 경우가 생길 수 있음.
FCFS(First Come First Serve) : 제일 오래 기다린 애 부터
SJF(Shortest Job First) : 제일 짧은애부터
HRN (Highest Response Ratio Next) : 계속 짧은애만 하면 starvation 발생 (무한 대기) -> 기다린 시간을 고려하여 기다린시간+실행해야하는시간실행해야하는시간 에 따른 우선순위.
- 선점 스케줄링 (Preemptive)
CPU가 할당되어도 강제 종료가 가능 -> 우선순위 높은 애가 빼앗아 사용.
응답성이 중요한 대화식 시스템에 사용 (ex) 파워포인트)
강제 종료를 위해 timer interrupt를 사용해야 함. 오버헤드가 큼
Round Robin : 할당된 시간이 끝나면 바뀜. (우선순위별 할당 시간 다를 수 있음)
SRT(Shortest Remaining Time) : 제일 시간 짧게 남은 애부터.
Multilevel queue : 우선순위에 따른 여러 Ready Queue 사용.
Multilevel feedback queue : MLQ에서 자기의 할당 시간을 다 채우면 우선순위 밑으로, 다 채우지 못한 애는 동일한 우선순위의 큐로 복귀하는 방식.
I/O bound 프로세스에 CPU bound 프로세스보다 상대적으로 높은 우선순위 부여 (빠르게 0번 우선순위 큐로 복귀)
전문가가 아니라 정확하지 않은 지식이 담겨있을 수 있습니다.
언제든지 댓글로 의견을 남겨주세요!
'컴퓨터 > 정보처리기사' 카테고리의 다른 글
| IT 프로젝트 정보 시스템 구축 관리 (1) - (정보시스템 구축 관리) [정보처리기사 필기] (0) | 2021.02.27 |
|---|---|
| 소프트웨어 개발 방법론 활용 정리 - (정보시스템 구축 관리) [정보처리기사 필기] (0) | 2021.02.27 |
| 응용 SW 기초 기술 활용 (통신) - (프로그래밍 언어 활용) [정보처리기사 필기] (0) | 2021.02.25 |
| 요구사항 확인 (2) - (소프트웨어 설계) [정보처리기사 필기] (0) | 2021.02.14 |
| 요구사항 확인 (1) - (소프트웨어 설계) [정보처리기사 필기] (0) | 2021.02.14 |
Comment